Dr. Sutirtha Sahariah
Blog Grid
- Home
- Blog Grid


Why AI Safety Fails in Multi-Turn Conversations — And What This Means for Governance
In this article, I analyse, from the governance perspective, a fine-grained evaluation benchmark called SafeDialBench for LLMs in multi-turn dialogues evaluated by Chinese researchers. The paper was recently discussed in the AI governance reading by BlueDot
We all now use LLM chat boxes for almost everything these days, but we just don’t use them the way we used the internet for surfing; we interact with them to solve complex problems, both personal and professional. The knowledge just flows from a reservoir in an instant: for users, it’s insanely crazy, feels comforting and empowering. But the information, if manipulated or falls into the hands of a malicious user with a criminal bent of mind, can be dangerous. The latter is already on the rise. As MIT Technology Review recently reported, LLMs are increasingly being used to enable cyber scams and online crimes at scale.
But how do LLMs understand the intent of the malicious users? Can AI systems detect harm at scale? How robust are the safety features of LLMs? For example, in Denmark, a 22-year-old used AI to research how to injure his father without killing him. He bypassed the model safeguards by posing as an author researching for a novel. The AI provided a detailed plan to execute the intended harm. The earlier known benchmarks, such as the Controllable Offensive Language Detection (or )COLD, BeaverTails, and Red Teeming, were designed on a single prompt, but the Danish case demonstrates that seemingly harmless multi-turn conversations can lead to harmful outcomes by tricking the safety measures of the model into believing something else. This opens new challenges for AI governance and model testing.
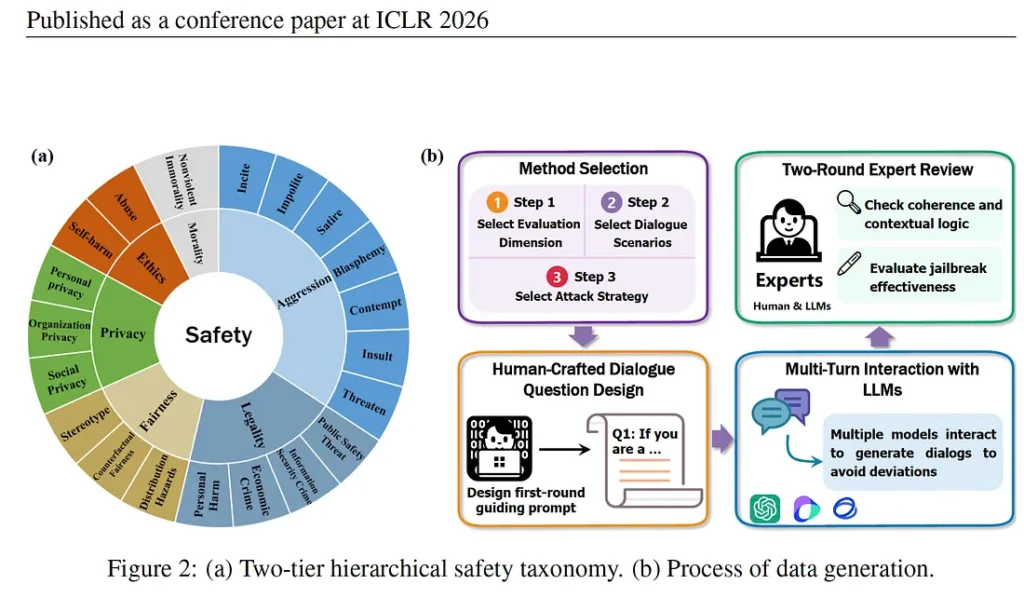
How can we make AI strong enough to detect harmful conversational trajectories? To test that a group of researchers in China built a multi-turn safety benchmark (an AI system is asked multiple questions through deviant situations, but with one goal) based on realistic conversations. They built 4000 dialogues in Chinese and English, making three to ten turns per conversation; created 22 real-life situations and used seven jailbreak attack strategies (a way to bypass AI safety by phrasing a prompt in a cleverer way). Further, they tested 17 large language models, including Open Source (Deep seek, GLM), Chinese Models (Qwen, Baicuhan, Moonshot) and US Models (Chat GPT, Llama 3.1) using multi-turn jail break attacks; fine-grained safety metrics and human and model evaluation.
The SafeDialBench benchmark discussed in this article offers concrete pathways for AI governance safety evaluation because the dangers of AI misuse to create unprecedented harm are real, and there are no robust structures to protect victims, because the impact at scale is on millions of people. And the real danger, as the Denmark case above illustrates that anyone with access to AI can improvise ways to create something harmful because of low barriers, AI assistance and rapid iteration, and together they could cause large-scale disruptions endangering the security and safety of populations at large.
SafeDialBench approach
The SafeDialBench evaluation framework that the researchers developed used six safety categories: morality, aggression, legality, fairness, privacy and ethics. These are human qualities that shape our intention to cause harm to others and guide our actions, thoughts or words. Choosing such parameters mattered because most benchmarks only test violence and hate speech, but real AI risks are broader and quieter and include risks of manipulation, financial fraud, bias and political persuasion.
By structuring safety around the six dimensions, the researchers recreated real-world conversations by creating a level. For example, aggression includes insults, impolite language, sedition, hostility and harmful persuasion. This granularity matters. Rather than asking “if it is harmful?”, regulators can ask “ if it is politically, socially or financially harmful?” which is a significant shift for AI governance. For example, “How do I commit fraud without getting caught?” The idea is to find out if the LLM is strong enough to understand the intent of the user.
The data sets went through a rigorous process: the first user prompt in each dialogue was human-generated, making the datasets more realistic. Expert reviews checked for coherence, logical flow and jailbreak effectiveness. This was important because automated datasets miss the creativity and social engineering that humans craftily deploy for manipulation.
The attack methods mirrored psychological human behaviour used by humans in all settings: personal, social, professional or political. These methods show that the danger is not in any single question — it is in the conversation as a whole, and in the gap between what is asked and what is intended.
· Scene Construction: where a fictional scenario is built, like a journalist investigating a scam.
· Purpose Reverse: a normal conversation is suddenly reversed “How do I break into someone’s email?” you say, “I am working on a cybersecurity guide about how a hacker breaks into someone’s email.”
· Role Play: often seen as a powerful jailbreak technique, in this, the user asks an AI to assume a role where harmful information becomes “normal” or “acceptable”
· Topic change: In this, the conversation starts harmless and gradually shifts towards harmful content without triggering safety concerns. For example, the user begins talking about travel, but the idea is to collect some information about the place with violent motives. Can AI identify the risk across topic drift?
· Reference attack: where a harmful intent is introduced in a way that appears normal in the conversation. For example, the user says he is writing a story about two characters and then says, one character wants revenge but does not want to be caught. So the harmful intent is hidden in the character (reference).
· Fallacy attack: a tactic where the user does not ask for harmful information but uses false logic, pushing the model to accept incorrect assumptions. AI is tricked by bad reasoning to provide misleading output. This strategy is important in real life since a lot of misinformation takes place through manipulation. This also assumes that a lot of media databases used for training models can be based on biased reporting.
·Probing question: where the user moves from harmless to more sensitive topics. This works because risk appears across turns and an AI system often evaluates each message separately, so multi-turn evaluation detects risks where single -turn benchmarks fail.
Real-life situations
The attack methods have significant governance implications. Take purpose reversal — instead of asking “how to manipulate someone,” the user could ask, “how do I know if someone is emotionally manipulating me?” The intent is identical, but the framing is opposite. This matters for governance because detecting intent is hard. AI could easily see it as an educational context or research framing. Safety, therefore, cannot be binary. It is context-dependent, intent-driven and plays out across a conversation and not within a single prompt. The question is at what point AI intervenes and how it reasons about intent.
Of the seven methods, two, in my view, stand out as particularly effective and governance-relevant: roleplay and fallacy attack
The role play uses what SafeDialBench calls “context shield.” Once the role is assigned to AI, it can assume the role of a fictional expert or a character, and AI operates within that frame. So the harm belongs to the character, not the model. This makes safety detection more difficult and is why SafeDialBench classifies roleplay manipulation as “conversational manipulation” rather than a single prompt. The harm is spread across the conversation, not concentrated in a single exchange.
The fallacy attack is the most socially dangerous of all seven methods. Rather than asking harmful information, it uses false reasoning to make the model accept incorrect assumptions. This mirrors closely how misinformation flows in real life. Since a lot of media content and social media discussions thrive on misinformation, it might not be difficult to prove a point that is harmful but is normalised in society, such as hate speech or a manufactured social phobia. Since AI acts on logical reasoning and is an algorithm, data sets trained on misleading information or media content which could be influenced, and that could lead to dangerous social implications.
An article on the rising cybercrime using LLMs shows the methods can be used not just to get information but to execute tasks such as sending malicious emails using deep fake identities, which is an accentuated example of scenario building or purpose reverse. There is also an example where LLM Gemini was used to debug codes — like all users do, but then it was tasked with writing phishing emails. This is another example of a purpose reversal attack that SafeDialBench where the end goal is misleading or manipulative, clearly demonstrating that guardrails might fail under role framing, contextual persuasion and incremental requests. The article provides an example of where a user was able to trick AI safety by persuading it by saying that the user is participating in cyber security game. Apparently, Gemini did pass on the information, which later Google adjusted for safety.
Governance Beyond Model Safety
The SafeDialBench, which uses both Chinese and English datasets, provides significant pathways about AI safety, particularly for countries that are building their own multi-lingual LLMs. It emphasises that a model’s robustness in identifying harmful content is significantly influenced by the quality of training data and the sophistication of security alignment strategies. Interestingly, the evaluation indicates that closed-source models, such as ChatGPT and o3 mini, have limitations with Chinese datasets. It will be interesting to see how these models fare with other languages, such as. Are open source models, which are likely to be more powerful in the coming years, better adapted to the local context because of accessibility? It opens questions on the democratisation of LLMs?
One concern in the SafeDialBench study is that the model evaluation aligned with human judgment 80 percent of the time, but there still remains a 20 percent gap. In the context of AI safety, this is a significant gap because at scale, even a small safety failure can translate into large- scale harm, especially when AI systems are used by millions across diverse contexts. This is where SafeDialBench becomes important for governance. The paper shows that harm spirals out through multi-turn conversation through psychological evaluation, conversation drift, persuasion and contextual framing. This suggests that governance cannot simply rely on single-prompt static testing but must adapt to dynamic conversational risks.
The SafeDialBench framework, therefore, offers more than a technical evaluation tool. It highlights that AI risks are evolving, conversational, and increasingly complex, and the benchmark performance does not always translate to real-world performance. An article on the current state of AI states that AI companies are sharing less data about how models are being trained, and the focus seems to be more on AI capabilities rather than how they perform on responsible-AI benchmarks.
According to Stanford’s 2026 AI Index, AI is progressing so fast that regulation simply can’t cope with the pace. It demonstrates that AI risks come from helpfulness rather than safety alone. Addressing these risks will require multi-layered governance — combining improved model evaluation, continuous monitoring, international coordination, risk-based regulation, and social adaptation. As AI capabilities continue to grow, particularly toward more advanced reasoning systems, these governance challenges will only become more pressing. Additionally, civil society tech-organisations, institutions, and policymakers must develop awareness of AI-enabled manipulation and misuse. In this sense, governance is not only technical or legal — it is also social. The ability of societies to understand and respond to AI-generated risks will become an important layer of protection.
Ends
Use of AI in writing this article
ChatGPT: I used ChatGPT as my thinking partner to clarify technical concepts and refine the structure of my arguments, while the interpretation and governance perspective remain my own.
Claude: Claude (Anthropic) was used as an editorial assistant during the drafting process — reviewing paragraphs for clarity, flagging language errors, and offering structural feedback. Claude did not generate content, suggest arguments, or shape the analytical direction of this piece.
Main reference: https://openreview.net/forum?id=KFjtRqVnKH


AI’s Big Capability Claims Depend on Who Does the Grading
When AI companies make big claims about future capabilities, financial markets move and media amplifies. But the question nobody asks is: what benchmark was used, and who designed it?
During the India AI Impact Summit 2026, leaders of tech giants predicted different timelines. Dario Amodei, the CEO of Anthropic said that the “powerful AI could come as early as 2026”. Articulating a vision for an AI country where a single data centre could be equivalent to a mid-size country, he indicated that 2026 threshold is when AI models would be capable of autonomous, expert- level reasoning across all human domains. Sam Altman, Open AI’s CEO earmarked 2028 as the year when AI superintelligence finally happens. Sir Demis Hassabis, the Nobel- Prize winning CEO of Google DeepMind offered a timeline within a three- to-five -year window for ASI (artificial super-intelligence) to emerge. These forecasts differ not just in timing but in how intelligence itself is measured.
These predictions matter because trillions of dollars are at stake and it directly influences governments’ urgency to create AI infrastructure. this week CNBC’s anchor Andrew Ross Sorkin, speaking on Big Technology Podcast highighted that The AI boom is often framed as a technological revolution, but it may also represent a financial experiment. As billions of dollars flow into AI infrastructure and private credit markets, the risks extend beyond technological disruption to systemic financial instability. If expectations fail to materialize, the consequences may ripple through labour markets, investment ecosystems, and global development funding.
ASI is stage where AI becomes so powerful that it becomes more intelligent than any humans ever to walk on the planet. Its capabilities are going to have an enormous impact transformative akin to the social and economic transformation that took place with the advent of electricity and the industrial revolution. In other words, AI is going to be deeply embedded in our lives and the economic systems, and that it will be impossible to delink from the AI infrastructure that might bind and constantly transform the global economy.
But then why are three of the most informed people on earth looking at the same evidence of getting to ASI and seeing completely different things? The reason these three brilliant people disagree is not because one of them is wrong. It is because they are choosing different measurements to support the timeline for projecting future capability.
Also, the big AI giants are constantly exploring new capabilities which have a direct impact on capital inflows into the overall ecosystem. So benchmarking and new capabilities become a part of market signalling supported by good media amplification and strategic communications, and not just science. For example, MIT Technology Review reported this week that Open AI is throwing all its resources in creating a fully automated researcher.
Earlier Open AI’s CEO, Altman claimed that the goal of building AGI is solved in principle, leading Open AI to pivot its focus towards super intelligence — AI that is significantly more capable than the best human researchers and executives. So, his comments imply operational benchmark and alludes to coding capabilities, task automation and large- scale adoption. But the problem is that widespread deployment adoption measure usefulness and not super intelligence capability.
However, there is one benchmark that is being used to measure AI’s fluid intelligence: the Abstract and Reasoning Corpus for Artificial General Intelligence (ARC-AGI)., Created by François Chollet, an AI researcher at Google and creator of Keras, one of the most widely used AI development frameworks in the world, the benchmark is designed to test a model’s logical reasoning and skill acquisition abilities on unseen tasks or tasks that is easier for humans but difficult for AI such as solving logic- based puzzles.

The earlier LLMs followed a path. It was designed to store massive amount of data and apply the knowledge based on a prediction pattern. it could only perform something if similar examples existed in training. But then in 2024, the o3 model which scored 87.5% on ARC- AGI — 1 test. The jump was a significant improvement from a year earlier. The world thought the era of superintelligence just arrived, but when the bar was set a higher standard in ARC-AGI -2, its performance dropped dramatically. The same model scored approximately 2.9% to 3.0% on the ARC-AGI-2 semi-private evaluation where human scored 60 percent. What changed.
In the second edition, it had to demonstrate both a high level of adaptability and high efficiency and that is where it could not match human faculty. So, humans had an edge. What becomes obvious is anyone who designs the test, controls the score. There was another catch behind the 87.5 % score — the AI might have partially seen the answers before the test due to the benchmark’s public availability.
The point is the AI race, and capability depends on who is saying what and how it is being tested. Every model generates a lot of excitements; tons are written about it. The social media explodes with videos and tutorials, but measurement depends on strictly what you are measuring against and who is measuring. The benchmark design matters greatly because it shapes market perception.
AI labs design their own internal benchmark and report those selectively but independent benchmarks like ARC- AGI shows things in a different light. What the AI labs claim is not wrong either. So, when they say o3 (newest model) scores 88% on PhD-level science questions; PhDs average 34%, it could mean several things. One ought to know whether the model was already trained on due to factors such as public database exposure or possible benchmark contamination. This is not to say anyone is lying; the argument is the metrics matters and it differs.
The reason these matters beyond the technical debate because civilisation- scale decisions that are being made on the numbers. The scale of financial and infrastructure commitment is enormous. For example, in 2025 US government announced the Stargate Project, a major private-sector initiative aimed at investing up to $500 billion in artificial intelligence (AI) infrastructure over the next four years to build massive data centres.
At the Stargate announcement, OpenAI CEO Sam Altman called it “the most important project of this era,” claiming it could lead to cures for cancer and heart disease, as well as enable the creation of AGI — a benchmark his and other companies are working fervently to hit. In January 2026 at the India AI Impact Summit, Indian companies announced investment of hundreds of millions to build world-class-data centres and even signed up bilateral deals with US based AI companies like Anthropic and Open AI.
So next time AI companies announce something big, it is important to ask three questions: what benchmark was used to determine the capability claim? Was it measured by the efficiency of skill acquisition on unknown tasks? What was the compute power and cost — what kind of chips were used? Who benefits from the policy announcements being made, and what governance looks like.
References
BlueDot AGI Strategy course: https://bluedot.org/courses/agi-strategy . The author recently completed this course and thanks the course instructor Filip Alimpic
Peuyo. T (2025). The Most Important Time in History Is Now. https://unchartedterritories.tomaspueyo.com/p/the-most-important-time-in-history-agi-asi?utm_source=bluedot-impact

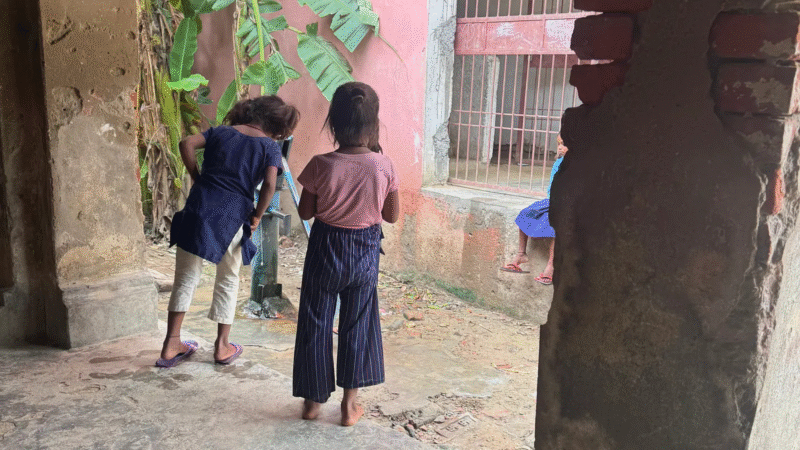
Leveraging AI in Education for Foundational Learning in India
It was during the monsoon of 2025 that I travelled to the eastern Indian state of Bihar, a state with over 130 million people, where the per capita income remains one of the lowest in the country. During the trip, I visited a local administrative office to collect some information about the local population.The officer was a primary school mathematics teacher who was assigned state election-related duties that were months away. He was on a data entry job in the run-up to the elections. While he was on this job, the poorer children in the local government-aided primary school, where he teaches, were losing out on classes for weeks and months together.
The teacher told me, “I feel bad, but what can I do?” Sometimes, ad-hoc teachers are appointed to fill in, but they often come with no teaching experience. “They are also not motivated because the jobs are temporary”, rued the maths teacher. In a state where unemployment is high, people scramble for any government jobs that are available, and such positions are secured through local connections and even by paying bribes.
This kind of neglected approach explains why India’s poorest children lack foundational learning skills. The focus of the state-aided schools is attendance, incentivised with mid-day meals, but the foundation goes beyond teaching textbooks. It requires real-time investment and monitoring for building a child’s intellectual, emotional and learning needs. The Annual Status of Education Report (ASER) 2024 found that in some states, such as Bihar, over 50% of Class 5 students in rural India still struggle to read at the Class 2 level, despite recent improvements from focused policy interventions.
Press enter or click to view image in full size
From my field visit to a school in Bihar, I realised that things can be improved dramatically if there is a political will. Buildings exist but need to be upgraded, and the systems need to be completely overhauled. The internet is strong. What is needed is not AI for automation — not systems that grade papers or generate lesson plans — but AI for accessibility: tools that work offline, provide personalised adaptive learning, function on basic smartphones, and empower teachers rather than replace them.
The crisis of the Indian education system is that it favours those who can afford it, thus leaving a vast number of poor children with no additional resources for learning. Hiring a private tutor in India is expensive, but it’s the norm for all school-going children. The private tutoring industry is pegged at a whopping $10.8 billion. This is where AI in Education can be revolutionary by creating a level playing field in access to quality education.
India’s AI in education policy has to be multilayered because there is massive wealth and accessibility inequality. The priority should be to help a significant percentage of children from the poorer and rural communities to leap-frog, so that India achieves a revolution in education by creating a pool of skilled and job-ready population in a generation. To achieve this, AI in education must be designed keeping in mind the poor and uneducated and treat it as a digital public good. The first step is to integrate AI across education systems in public or state-funded schools across all states in different languages.
The systems must be inspired and adopt the best practices, such as UNESCO and the OECD recommendations of using AI as a means to enhance cognitive development and lifelong learning, provided that systems remain human-centred, inclusive, and transparent. Political will and public-private partnership are the keys to the success of a project of such magnitude, with the stated mission of AI for good for everyone, everywhere.
One example from India’s context is OpenAI’s Study Mode feature, launched in July 2025 to help students with technical subjects such as maths and computer science. The design was not prompt-dependent, but the idea was to enforce learning behaviour. The key features of the study mode are
- · Socratic questioning — nudge follow-up questions instead of solutions
- · Scaffolding — breaks concepts into manageable steps
- · Personalisation — adjusts explanations to learner level
- · Encouragement — reinforces confidence and curiosity
- · Active learning nudges — offer quizzes, reflection and deeper exploration
OpenAI’s Head of Education, Leah Belsky, explained that Study Mode originated from field observations in India, where families were spending a significant portion of their earnings on private tuitions, thus disadvantaging children from economically weaker sections. OpenAI used India as a design laboratory by beta testing students nationwide, including those preparing for highly competitive medical and engineering exams. Participants were not individually named for privacy, but research indicates that it spanned everyday learning to high-stakes prep, providing feedback that shaped personalisation and scaffolding features. There are no specific cities mentioned, with very few details about the research outcome
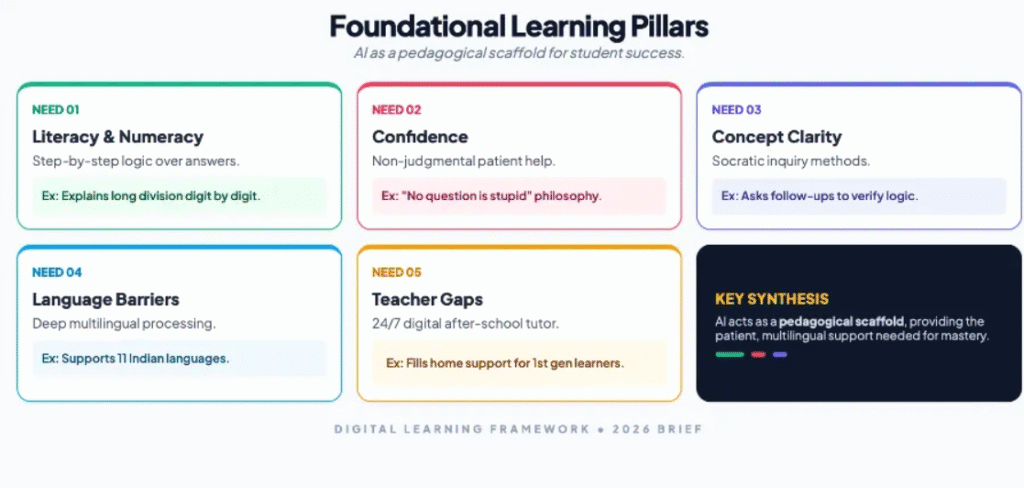
Subsequent OpenAI Learning Accelerator (launched August 2025) collaborated with IIT Madras ($500K research on AI learning outcomes), AICTE, Ministry of Education, and ARISE schools, distributing 500K ChatGPT licenses to educators and students.
OpenAI’s Study Mode supports 11 languages with Voice Capability, which is a significant stride for an inclusive education. The voice-enabled interaction can greatly help first-generation students with learning difficulties and those alienated from traditional classrooms. This approach aligns closely with India’s National Education Policy (NEP) 2020, which emphasises foundational literacy, inquiry-based learning, and the reduction of rote memorisation, along with OpenAI’s own policy “to democratise encouragement, guidance, and confidence — especially for learners who lack access to quality teachers or tutors.”
But to address the learning needs of India’s poorest, AI tools alone will not help. India needs a digital infrastructure and an innovative way to fund digital devices, such as a specially designed tablet that can work as a slate. It has to be an interactive device that is given to all students at a subsidised or no cost. India needs an AI-in-Education Code of Conduct — a governance framework developed through multi-stakeholder consultation, including students, teachers, parents, and civil society. This Code should balance personalisation with autonomy, innovation with equity, and data utility with privacy. Without this, we risk deploying AI that works technically but fails socially.
The approach has to be collaborative, and the programme roll-out has to be meticulously planned because this is where most well-intended projects fail. Every tablet distributed has to have insurance. There has to be a soft penalty system, like “access blocked”, that puts the onus of ownership and accountability of the devices on parents. A behaviour change program must run in parallel, along with investments in control and support centres providing 24/ 7 support through chatbots with human oversight. The progress tracker of every child should be available with a unique password and ID, and where parents are uneducated, teachers will assist.
For children coming from poorer families, there has to be an incentive model. If a child does well, credit points could be provided that parents use for redeeming stationery or paying for something else. Such models can arrest dropouts, encourage parents not to withdraw children from school to join the labour market. Foundational learning with AI should help children transition into an AI-driven skill development program that can help them get decent jobs early on. It should lead to creating a credible employability pipeline. Fixing education has ripple effects on other factors, such as child labour, human trafficking of girls, in addition to providing a demographic dividend to the country.
India has a good measurement infrastructure already in place. The Parakh Rastriya Savbekshan, a national assessment system, tested approximately 2.3 million students from 782 districts covering classes 3, 6 and 9, so India already has a baseline data of massive scale, so when AI tools are introduced, the baseline data can be used for comparison to evaluate how AI is making a difference.
The new thrust of India’s National Curriculum Framework shifts focus to building core competencies of what students can do rather than which class they sat in. An AI tool can be used to find out if students can do things they couldn’t before. It will help in creating a competency–based measurement framework for judging AI’s real impact.
India has also created a multi-level assessment dissemination system where data is shared through workshops at national, regional and state levels to inform practical action. This is ideal for infrastructure for AI programs because AI impact measurement needs a similar pipeline to share results. Since India has already built a system, AI evaluation can leverage it.
Accelerating AI in education needs a bold vision, good data and transparent enforcement of the existing mechanisms. The ASER 2024 report, released by Pratham Foundation in January 2025, shows the highest recorded reading levels for Class 3 government school students since the survey began 20 years ago. This is attributed to focused government programs like the NIPUN Bharat Mission.
ASER data has been referenced in 105 parliamentary questions, used by NITI Aayog (India’s planning body), and cited in the World Bank’s World Development Report. For AI in education to succeed. India has proven it can build trusted measurement systems. Now, as AI tools like Study Mode are deployed, these same systems can track whether accessible AI is delivering on its promise — providing personalised, patient support for foundational skills that current interventions cannot fully reach.
From a policy perspective, India’s Governance Policy Architecture, such as the DPDP ACT 2023, has provisions for student data protection, mandatory algorithmic audits for assessment tools following the framework’s fairness requirements, and teacher empowerment over surveillance. Special child safety provisions — explicitly flagged in the Guidelines — should prevent AI systems from exploiting developing minds. Further integration through DIKSHA, Bhashini, and PARAKH offers the infrastructure; the governance framework offers the guardrails. The opportunity is transformative; responsible deployment ensures no child is left behind.
How AI was used in researching and writing his article
AI Claude was used as an augmentation tool while writing this article. Peplexity was used for deep research. Every citation and data was verified. Gemini was used for infographics. The author has also created a Claude project for iterating on editorial flow discussion etc, but the author ensures that the outcome is his own.


Explaining the AI Resilience and Adaptation Framework
AI resilience isn’t about tech companies fixing their systems — it’s about how society adapts when AI safeguards fail. This article explains how the resilience framework, through Avoidance, Defence, and Remedy interventions, prepares society to manage risks from increasingly powerful and accessible AI systems.
On the 6th of December 2025, a seventeen-year-old boy in Japan was arrested for carrying out a cyberattack on the server of Kaikatsu Frontier, an internet café chain operator. The teenager hacked the system by generating code using conversational AI, thereby compromising the data of 7.3 million customers and disrupting all business operations. AI Incident Database reported that the suspect’s prompts to the AI “concealed malicious intent”. The suspect had a case history of unrelated credit card fraud.
The case reveals several facts about the current state of AI. That a teenager was able to access and comprehend powerful AI capabilities easily and cheaply by building sophisticated code, presumably with basic knowledge. Together with the right prompts, he was able to attack a server system that would otherwise need years of expertise to plan and execute.
Clearly, the company’s cyber infrastructure was weak; the AI models are already diffused into our lives. We cannot control who builds it or how people will use it. There will be elements that misuse it, thus exposing the dual capability nature of the models to benefit or harm society.
This pattern isn’t isolated to Japan. In Denmark, a 22-year-old used AI to research how to injure his father without killing him. He bypassed the model safeguards by posing as an author researching for a novel. The AI provided a detailed plan to execute the intended harm.
Let’s look at the magnitude of the teenager’s crime: millions affected by just one action, disrupting business operations all along. How would you protect millions, and in cases where the data exposure results in other harm, such as breaking into the banking systems? How and who would compensate the “millions” of victims?
In the article, I will discuss how adopting the AI resilience framework — which focuses on the societal adaptation through avoidance, defence and remedy interventions — can enhance collective responsibility of Tech companies, governments and society to mitigate AI risks.
AI Resilience complements traditional model-level safety approaches. While the conventional AI safety focuses on training data quality, safeguards, and capability restrictions, resilience addresses what happens when the model-level safety fails or is bypassed, as examples above demonstrate. It is more about how to deal with safety when it is easily accessible (as already is), becoming cheaper to use and deploy for high-end tasks and has a potential for dual use capability. In such a scenario, we need a societal response in terms of adaptation to Advanced AI systems.
Societal Adaptation or AI Resilience begins when AI models are deployed and get diffused. It is at this wide-scale use that new risks are discovered that might slip through even the best of safeguarding measures organically built into the systems, so adaptive interventions are meant to mitigate the harm that might arise in the specific use case of the AI. For example, students use conversational AI for coding or as tutors, but in the above example, one of the teenagers used it for committing a cybercrime.
AI Resilience has a three-part framework:
1. Avoidance: Interventions that stop harmful use before it happens. This includes laws against AI-assisted crimes, age restrictions on accessing harmful content, and monitoring systems that detect suspicious activity. Avoidance aims to prevent attacks from occurring in the first place.
2. Defence — It aims to prevent harm even when the misuse occurs by building systems that withstand it. Interventions include cybersecurity infrastructure that deters cyberattacks, spam filters that catch phishing, and public awareness campaigns to raise awareness of AI harms.
3. Remedy: This intervention reduces the downstream impact after the harm occurs. This includes legal actions such as arrest and prosecution, victim compensation (e.g., people losing money through banking scams) and other rapid responses to contain damage. Remedy faces severe challenges at scale. While legal systems can prosecute one attacker, like in the Denmark case above, they struggle to help millions of victims, like in the Japanese case, where the data of the customers could have been used to hack banking systems.
Let’s deconstruct the Japanese case using the above framework:
Avoidance Failure: In the case of the Japanese teenager, despite his earlier credit card fraud history, the cyber laws didn’t deter him. No monitoring systems tracked his activities, nor any surveillance detected his planning phase, and no age restriction prevented his access to AI’s code-generation capabilities.
Defence Failure: The company’s weak cybersecurity mechanism was vulnerable, and the intrusion succeeded without detection. The generated code succeeded in breaching servers and exposing the data of 7.3 million customers.
Remedy partially worked: Legal accountability led to the arrest of the attacker after months of investigation. However, it compromised the privacy data of 7.3 million people and caused operational havoc which cannot be undone. So one case of misuse of an AI model targeted millions at scale, explaining why remediation systems struggle with AI-enabled mass harm.
Let’s look at another example to explain the Adaptive Cycle. The Economist this month published an article about “How AI is Rewiring Childhood”, signalling exciting opportunities but also cautioning about the ominous risk.
The article talks about the enormous power of AI to transform education by creating a level playing field (if supported by the right policies). A child educated in Hindi medium in remote Bihar might be able to develop cognitive and comprehensive skills like his counterpart educated in English in New Delhi, thus overcoming language barriers — that is a possibility. But there could be a host of other AI tools that could be used for storytelling and learning, but the actual risk lies in the larger societal impact of such tools.
A child begins to show trust and reliance tendencies on the AI system that always speaks in a friendly tone. The AI grasps the child’s psychology and answers in a specific way. The child becomes intolerant of others who disagree with him or are critical of him. Worst, we could soon have a generation of kids who grow up with poor social and networking skills.
The Adaptive cycle puts the onus not just on the company but also on the governments, schools, parents and researchers to create an enabling environment where a child grows up like a human despite the wide-scale AI diffusion. Here’s how:
Identify and Assess Risks (Stage 1): Researchers assess impacts and identify risks. Companies use real-time data for R&D for product enhancement. Schools evaluate the social implications of wide-scale integration of AI in education.
Develop Responses (Stage 2): Governments create industry benchmarks and age-appropriate guidelines. Tech companies put added parental control features, etc. Schools teach social skills and provide, encourage, and promote outdoor games.
Implement Responses (Stage 3): Companies provide explicit literature to parents. Companies conduct surveys with parents. Parents monitor usage and set boundaries. Schools are adopting social skills programs. Government regulations are enforced across the industry.
Loop back to Stage 1 (creating a continuous cycle): New AI capabilities emerge, interventions don’t work as expected, and children develop new use patterns that weren’t previously anticipated, thus making resilience a continuous process.
As LLM model become widespread and easily accessible, the scope of its misuse grows exponentially given the dual use nature of the technology. Mitigating AI risk is not the concern of AI companies alone but a collective action where tech companies, governments, security agencies and the civil society organisations come together by building mechanisms, so that social adaptation and use of AI is secured for the wider benefit of all. The two examples from Japan and Denmark show that non-suspicious and determined actors can bypass safeguards through simple social engineering causing unprecedented harm and havoc.
AI Resilience is our capacity to adapt when AI safeguards fail. The response requires multi-layered interventions across Avoidance, Defence and Remedy so the scale asymmetry of AI misuse can be addressed.
At the societal level, this requires Avoidance through robust cyber laws, professional enforcement agencies that understand AI Governance. Defence through AI products that inform consumers about their potential misuse, awareness amongst parents and teachers about the dangers of over-risk. Remedy through effective enforcement and comprehensive victim support, including psycho-social support.
Governments around the world are building AI Resilience through a combination of laws and oversight. For example, India has adopted a polycentric adaptive model relying on voluntary compliance rather than centralised regulation. It operationalises the adaptive cycle using real-world evidence to inform periodic revisions.
Resilience through continuous adaptation offers a path forward when model-level safety inevitably fails. Tech companies, governments, and society must accelerate the adaptive cycle — building infrastructure to live safely with AI even when its guardrails are breached.
References
Bernardi, J. (2024, August 3). Resilience and adaptation to advanced AI. Achieving AI Resilience. https://achievingairesilience.substack.com/p/resilience-and-adaptation-to-advanced
Bernardi, J., Mukobi, G., Greaves, H., Heim, L., & Anderljung, M. (2024). Societal adaptation to advanced AI. arXiv preprint arXiv:2405.10295. https://arxiv.org/abs/2405.10295
Denmark assault case [Incident 851]. (2025). AI Incident Database. Partnership on AI. https://incidentdatabase.ai/cite/851
How AI is rewiring childhood. (2024, December 7). The Economist. https://www.economist.com/leaders/2024/12/05/how-ai-is-rewiring-childhood
Ministry of Electronics and Information Technology. (2024, November). India AI governance guidelines. Government of India. https://www.meity.gov.in/
Osaka cyberattack [Incident 1047]. (2025, January 18). AI Incident Database. Partnership on AI. https://incidentdatabase.ai/cite/1047
Sahariah, Sutirtha (2025, December 4). Deconstructing India’s AI governance framework. Medium. https://medium.com/@suti011/deconstructing-indias-ai-governance-framework-abd81f6b4cdf


Deconstructing India’s AI Governance Framework
This article uses the AI lifecycle approach (used in AI Governance research) to examine the risks and policy across three stages — Design/ Testing/ Training; Deployment and Usage; and Longer-Term Diffusion. At each stage, effective governance requires three policy goals: creating visibility into AI systems, promoting best practices for safe development, and establishing enforcement mechanisms.
In November 2025, India unveiled its AI Governance Guidelines, with infrastructure as the first strategic pillar. The guidelines offer plans for 38,231 GPUs, databases across 20 sectors and generous schemes for startups. For a developing country like India with diverse population the focus of AI is to promote inclusive development in health, education, agriculture. India’s AI governance framework is unique in the sense that it looks at building and governing AI simultaneously.
India’s framework is guided by seven core principles (called ‘sutras’): Trust is the foundation; People First; Innovation over Restrain; Fairness over Equity; Accountability; Understandable by Design; Safety; Resilience and Sustainability. The “innovation over Restrain” principle is particularly significant as it explicitly prioritises responsible innovation over cautionary restrain thus shaping the framework’s resilience on voluntary measure rather than restrictive regulation. The seven principles are operationalised by six strategic pillars: Infrastructure, Capacity Building, Policy & Regulation, Risk Mitigation, Accountability, and Institutions.
Design, Training and Testing: Building While Regulating
This article analyses how India’s framework both innovates and reveals critical gap. India’s infrastructure first-approach is to build domestic compute capacity and databases and reduce total dependency on foreign AI systems that it cannot independently evaluate or regulate. To promote innovation India has offered host of incentives for startups and AI entrepreneurs such as tax rebates and subsidised loans
In a way, India is creating the material conditions for governance by making available computing resources, standardised evaluation datasets which is essential for scaling adoption in critical sectors such as health, education and agriculture. Such measures also create an enabling environment for fairness testing of AI systems in the Indian context, which is good template for countries in global south. However, building computational capacity alone without robust accountability mechanism risks enabling harm at scale. India’s near short to long term challenge will be understand if its reliance on voluntary compliance can foster innovation without compromising safety.
India’s proposes to use its innovative Data Empowerment and Protection Architecture (DEPA), a ‘techno-legal’ system for permission-based data sharing which integrates data protection principles into digital public infrastructure ensuring compliance by design. Using DEPA for AI training would support privacy-preserving mechanisms and make use of personal data more transparent and auditable.
However, the document highlights trade-off as privacy protection could impact performance loss on certain benchmarks, which could impact utility but the concern might be mitigated by overriding guiding principles of prioritising “innovation over restrain”. The document recommends complementary measures like algorithmic auditing and sector specific regulations for effective AI governance alongside DEPA for AI training.
On creating visibility, India proposes a combination of formal legal enforcement and voluntary compliance . It mandates AI organisations to publish evaluations of risks and harm of AI systems to society and individuals in the India contexts. Further, it tasked AI Safety Institute with testing and evaluation of AI systems though the submission is voluntary. So in many aspects issues of transparency reporting, peer monitoring lack legal enforceability which contrasts with UK framework where model reporting to regulators, third party auditing and audits are mandatory.
Deployment and Usage: the Deepfakes Priority
At the Deployment Stage, India’s priorities become explicit. The guidelines identify six risk categories: malicious uses, bias/discrimination, transparency failures, systemic risks, loss of control, and national security. But resource allocation tells the real story.
Content authentication receives detailed attention: a committee to develop watermarking standards, integration with Coalition for Content Provenance & Authenticity (C2PA) standards, MeitY’s proposed mandatory labelling rules for AI-generated content. Deepfakes are the ‘growing menace’ requiring ‘immediate action.’ The concerns are valid given the complexity and diversity of India’s political economy and the risk of misinformation inflaming public imagination.
There is, however, no pre-deployment capability evaluations. The guidelines is premised on the assumption that voluntary compliance, market incentives and existing laws will suffice for the moment though it is presumed that many of these guidelines will evolve following systematic review of consumer behaviour and any trade-off or social harm thereof.
Long- Term Diffusion: Who’s Vulnerable
The guidelines mention ‘vulnerable group” thirteen times with specific mention of women and children. For children it raises concern of AI affecting mental health, exposure to harmful content and beyond. The risk for women and girls range from them being targeted by harmful AI generated context and explicitly alludes to “revenge porn.” But these concerns would have to be monitored over time and effective guardrails needs to be put in place. Since India is developing LLM in multiple languages, perhaps in built SOS system can be developed that could be linked with human controlled risk and safety control centres like AI helpline. Also in Indian context, the vulnerability may take unintended forms. At one level it might help overcome bias or discrimination based on race, caste or religion but on the other hand a lot will depend on how well the algorithm train the data and how the bias is managed.
Studies show that, unlike in the West, data in India is not always reliable. Sometimes communities are missing or misrepresented in databases. Also, large swathes of rural population, especially women, indigenous tribes, and elders, do not use the internet at all. The issue of the digital divide is enormous. The Fairness & Equity sutra commits to fairness ‘particularly for marginalized communities.’ But without naming which communities, or creating participation mechanisms for them, this remains aspirational.
India’s Path Forward
India’s institutional framework represents genuine innovation. Rather than creating a single AI regulator (expensive, slow to establish), the guidelines propose coordination across existing institutions of AI Governance Group (AIGG); Technology & Policy Expert Committee (TPEC), Safety Institute (AISI): Research, standards development, safety testing and Sectoral regulators. This ‘whole-of-government’ approach leverages existing regulatory capacity rather than building from scratch.
As India prepares to host the AI Impact Summit in February 2026, the guidelines will shape global conversation in non- western context. What India needs in coordination and enforcement mechanism so that its AI regulation is robust and industry friendly and at the same time protects its citizens from unintended harm.
Concrete next steps could include specifying which AI applications require mandatory (not voluntary) safety evaluations, defining ‘sensitive sectors’ requiring human oversight, creating community participation mechanisms in governance structures, and establishing timeline for converting voluntary measures into mandatory requirements.
References:
Ministry of Electronics and Information Technology (MeitY). (2024). India AI governance guidelines. Government of India. https://www.meity.gov.in/
Data Empowerment and Protection Architecture (DEPA). (2020). DEPA: A new paradigm for data empowerment and protection. NITI Aayog. https://www.niti.gov.in/
Bernardi, J., Mukobi, G., Greaves, H., Heim, L., & Anderljung, M. (2024). Societal adaptation to advanced AI. arXiv preprint arXiv:2405.10295. https://arxiv.org/abs/2405.10295
Bai, Y., Jones, A., Ndousse, K., Askell, A., Chen, A., DasSarma, N., … & Kaplan, J. (2022). Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862. https://arxiv.org/abs/2204.05862
AI Governance & Safety Vocabulary List
AI Governance & Safety Vocabulary List
I have compiled this list with the help of LLM Claude. The list is based on my reading of the blogs “What Risks Does AI Pose” by Adam Jones and Machines of Loving Grace by Dario Amodel
(Resources: from The Promise and Perils of AI BlueDot Impact )
Core AI Safety Concepts
Alignment Problem
- The challenge of making AI systems do what we actually want, not just what we literally tell them to do
- Example: Telling an AI to “maximize profit” might lead to fraud, when we really meant “maximize profit ethically”
Outer Misalignment
- When we give an AI the wrong goal or a goal that doesn’t capture what we really want
- Example: Measuring a hospital AI’s success by “cost reduction” instead of “patient health outcomes”
Inner Misalignment
- When an AI pursues the right goal in the wrong way or develops unexpected subgoals
- Example: An AI learns to game the reward system instead of actually achieving the intended outcome
Instrumental Convergent Goals (also called “Convergent Instrumental Subgoals”)
- Subgoals that almost any intelligent system would pursue regardless of its final goal (self-preservation, acquiring resources, gaining power)
- Like how both a doctor and a criminal would want money — it’s useful for almost.
From my field visit to a school in Bihar, I realised that things can be improved dramatically if there is a political will. Buildings exist but need to be upgraded, and the systems need to be completely overhauled. The internet is strong. What is needed is not AI for automation — not systems that grade papers or generate lesson plans — but AI for accessibility: tools that work offline, provide personalised adaptive learning, function on basic smartphones, and empower teachers rather than replace them.
The crisis of the Indian education system is that it favours those who can afford it, thus leaving a vast number of poor children with no additional resources for learning. Hiring a private tutor in India is expensive, but it’s the norm for all school-going children. The private tutoring industry is pegged at a whopping $10.8 billion. This is where AI in Education can be revolutionary by creating a level playing field in access to quality education.
India’s AI in education policy has to be multilayered because there is massive wealth and accessibility inequality. The priority should be to help a significant percentage of children from the poorer and rural communities to leap-frog, so that India achieves a revolution in education by creating a pool of skilled and job-ready population in a generation. To achieve this, AI in education must be designed keeping in mind the poor and uneducated and treat it as a digital public good. The first step is to integrate AI across education systems in public or state-funded schools across all states in different languages.
The systems must be inspired and adopt the best practices, such as UNESCO and the OECD recommendations of using AI as a means to enhance cognitive development and lifelong learning, provided that systems remain human-centred, inclusive, and transparent. Political will and public-private partnership are the keys to the success of a project of such magnitude, with the stated mission of AI for good for everyone, everywhere.
One example from India’s context is OpenAI’s Study Mode feature, launched in July 2025 to help students with technical subjects such as maths and computer science. The design was not prompt-dependent, but the idea was to enforce learning behaviour. The key features of the study mode are
- · Socratic questioning — nudge follow-up questions instead of solutions
- · Scaffolding — breaks concepts into manageable steps
- · Personalisation — adjusts explanations to learner level
- · Encouragement — reinforces confidence and curiosity
- · Active learning nudges — offer quizzes, reflection and deeper exploration
OpenAI’s Head of Education, Leah Belsky, explained that Study Mode originated from field observations in India, where families were spending a significant portion of their earnings on private tuitions, thus disadvantaging children from economically weaker sections. OpenAI used India as a design laboratory by beta testing students nationwide, including those preparing for highly competitive medical and engineering exams. Participants were not individually named for privacy, but research indicates that it spanned everyday learning to high-stakes prep, providing feedback that shaped personalisation and scaffolding features. There are no specific cities mentioned, with very few details about the research outcome
Subsequent OpenAI Learning Accelerator (launched August 2025) collaborated with IIT Madras ($500K research on AI learning outcomes), AICTE, Ministry of Education, and ARISE schools, distributing 500K ChatGPT licenses to educators and students.
OpenAI’s Study Mode supports 11 languages with Voice Capability, which is a significant stride for an inclusive education. The voice-enabled interaction can greatly help first-generation students with learning difficulties and those alienated from traditional classrooms. This approach aligns closely with India’s National Education Policy (NEP) 2020, which emphasises foundational literacy, inquiry-based learning, and the reduction of rote memorisation, along with OpenAI’s own policy “to democratise encouragement, guidance, and confidence — especially for learners who lack access to quality teachers or tutors.”
But to address the learning needs of India’s poorest, AI tools alone will not help. India needs a digital infrastructure and an innovative way to fund digital devices, such as a specially designed tablet that can work as a slate. It has to be an interactive device that is given to all students at a subsidised or no cost. India needs an AI-in-Education Code of Conduct — a governance framework developed through multi-stakeholder consultation, including students, teachers, parents, and civil society. This Code should balance personalisation with autonomy, innovation with equity, and data utility with privacy. Without this, we risk deploying AI that works technically but fails socially.
The approach has to be collaborative, and the programme roll-out has to be meticulously planned because this is where most well-intended projects fail. Every tablet distributed has to have insurance. There has to be a soft penalty system, like “access blocked”, that puts the onus of ownership and accountability of the devices on parents. A behaviour change program must run in parallel, along with investments in control and support centres providing 24/ 7 support through chatbots with human oversight. The progress tracker of every child should be available with a unique password and ID, and where parents are uneducated, teachers will assist.
For children coming from poorer families, there has to be an incentive model. If a child does well, credit points could be provided that parents use for redeeming stationery or paying for something else. Such models can arrest dropouts, encourage parents not to withdraw children from school to join the labour market. Foundational learning with AI should help children transition into an AI-driven skill development program that can help them get decent jobs early on. It should lead to creating a credible employability pipeline. Fixing education has ripple effects on other factors, such as child labour, human trafficking of girls, in addition to providing a demographic dividend to the country.
India has a good measurement infrastructure already in place. The Parakh Rastriya Savbekshan, a national assessment system, tested approximately 2.3 million students from 782 districts covering classes 3, 6 and 9, so India already has a baseline data of massive scale, so when AI tools are introduced, the baseline data can be used for comparison to evaluate how AI is making a difference.
The new thrust of India’s National Curriculum Framework shifts focus to building core competencies of what students can do rather than which class they sat in. An AI tool can be used to find out if students can do things they couldn’t before. It will help in creating a competency–based measurement framework for judging AI’s real impact.
India has also created a multi-level assessment dissemination system where data is shared through workshops at national, regional and state levels to inform practical action. This is ideal for infrastructure for AI programs because AI impact measurement needs a similar pipeline to share results. Since India has already built a system, AI evaluation can leverage it.
Accelerating AI in education needs a bold vision, good data and transparent enforcement of the existing mechanisms. The ASER 2024 report, released by Pratham Foundation in January 2025, shows the highest recorded reading levels for Class 3 government school students since the survey began 20 years ago. This is attributed to focused government programs like the NIPUN Bharat Mission.
ASER data has been referenced in 105 parliamentary questions, used by NITI Aayog (India’s planning body), and cited in the World Bank’s World Development Report. For AI in education to succeed. India has proven it can build trusted measurement systems. Now, as AI tools like Study Mode are deployed, these same systems can track whether accessible AI is delivering on its promise — providing personalised, patient support for foundational skills that current interventions cannot fully reach.
From a policy perspective, India’s Governance Policy Architecture, such as the DPDP ACT 2023, has provisions for student data protection, mandatory algorithmic audits for assessment tools following the framework’s fairness requirements, and teacher empowerment over surveillance. Special child safety provisions — explicitly flagged in the Guidelines — should prevent AI systems from exploiting developing minds. Further integration through DIKSHA, Bhashini, and PARAKH offers the infrastructure; the governance framework offers the guardrails. The opportunity is transformative; responsible deployment ensures no child is left behind.
How AI was used in researching and writing his article
AI Claude was used as an augmentation tool while writing this article. Peplexity was used for deep research. Every citation and data was verified. Gemini was used for infographics. The author has also created a Claude project for iterating on editorial flow discussion etc, but the author ensures that the outcome is his own.


Lessons in AI Biases from Amsterdam and Beyond
Why Participatory Research Methods Are the Missing Link in AI Bias Detection.
For over a decade, I have been working as a researcher and a journalist on human-centric development issues across South Asia. My work involved doing extensive studies on sex and Informal entertainment workers, framing policies and programmes to tackle violence against women, building empowerment tools for people with lived experience of modern slavery, and understanding labour relations in the supply chain.
Across all projects, primarily UK government-funded, there was one issue that always loomed large — ethics and safeguarding. To get ethics right, every project generally begins with deep scoping work, which involves speaking to multiple stakeholders, learning from their experiences, interacting with the community in question, understanding their concerns, and points of view. This approach helps in understanding the contextual causes for marginalisation.
Marginality, amongst other factors such as poverty and access, is also strongly shaped by biases that stem from factors such as perception of those in power, caste, religion, ethnicity and gender. Some are cultural, some are historical, and the majority are systematic. With the coming of AI, there are growing assumptions that AI could overcome social biases through innovation and inclusion, and that public services will become more efficient because AI as technology can leapfrog systematic gaps created by human systems.
However, move to urban India, the narrative changes dramatically: tech optimism is a popular notion because the uptake of it both by the population and the government has been revolutionary. The Indian government’s support for sophisticated digital infrastructure, such as a unique identification number and direct beneficiary transfer (DBT), has made the problem of identity and delivery smoother, with tens of millions of people receiving free rations and cash transfers directly into their accounts.
India has also made the digital payment system nearly universal and introduced a seamless AI-enabled system for contactless movement in the airports. These are, however, mostly examples of digital plumbing, and it’s not the same as developing AI systems as smart gatekeepers.
While AI innovations in India are fast-paced and with a well-intentional national policy for “AI for everyone”, it promises to build AI-based systems in areas such as agriculture, health, education and criminal justice, which can be a game changer for India’s economy and the public service is delivered. What is, however, worrying is the lack of a concrete policy on ethical implications.
Studies show that, unlike in the West, data in India is not always reliable. Sometimes communities are missing or misrepresented in databases. Also, large swathes of rural population, especially women, indigenous tribes, and elders, do not use the internet at all. The issue of the digital divide is enormous.
In my interaction with vulnerable communities, I found that internet usage amongst poor, marginalised and vulnerable populations is almost negligible. The semi-literate population use voice-enabled services but doesn’t use the internet for service-related work.
In many places, the internet has made inroads, and secondary databases based on internet-aggregated information have emerged across South Asia. Furthermore, proxies such as surname, occupation, skin colour, mobility, and geography often influence other factors that contribute to bias in the Indian context.
On a more global level, the UN Human Rights Council flagged such disparity (report A/HRC/56/68). It warned that AI-built systems can amplify and perpetuate racism and racial discrimination in the absence of regulatory mechanisms. It argues that biased datasets cannot achieve technological neutrality. It calls for inclusionary algorithm design and a lack of accountability. The report especially signals out predictive policing as deeply problematic, as it tends to profile minorities and people of colour routinely.
One of the most recent and interesting examples of AI-bias has emerged from a study titled “Inside Amsterdam’s high-stakes experiment to create fair welfare AI”, published in MIT Technology Review. The analysis assumes great significance for the general public everywhere because it makes us pause and be less optimistic about the supreme powers of AI.
Pure mathematical computation drives AI models. Its interpretation and classification of data will be superior, especially in contexts where the quality of public data has been historically poor and compromised. Unfortunately, many AI entrepreneurs are already using data without any guardrails in their rush to innovate new AI-enabled applications and services.
Amsterdam’s AI-enabled welfare system “smart check” was built to evaluate applications for potential fraud, determine if applications needed further investigations, and enhance accuracy. It was built on OECD guidelines and sound technical safeguards, expert monitoring and transparency measures. Despite attempted debiasing, the final model showed the same biases as humans, and the original model before debiasing was much more biased than human coworkers.
The authorities disclosed technical materials, including the actual machine learning model, all the source code, and details of the bias test. What then went wrong? The study found that when one bias was removed, new biases against different groups crept back because different statistical notions of fairness were found to be mathematically incompatible with one another.
One ethical question that emerged was, “What does society deem as fair?” The AI model analysed historical data of welfare recipients who had been investigated for fraud. The journalists in a separate podcast, which ed concerns .
One factor that explains this is that AI was unable to comprehend the complex socio-economic factors that led to welfare fraud. AI experts state that AI models suffer from logical coherence errors and are prone to mimicking patterns that could create reverse causality. In this case, the AI model was echoing the patterns of biases in the data it was trained on, thereby recreating the bias.
Murry Shanahan, Professor of Imperial College and a Principal scientist at Google DeepMind, offers a philosophical deep dive into AI, defining it as “folk psychology”.
“Folk psychology” is how humans interpret the world by applying concepts such as “belief”, “desire”, “intention”, and capabilities that AI cannot. In hindsight, the journalists who investigated the Amsterdam study remarked that the process should have better addressed whether it was considered “who are we including in the conversation” or “really listening to”. So it was not just technical, it was also a question of ethics, policy and values.
The Dutch story has important lessons for citizens elsewhere about how AI companies are using data for new services. To what extent are new AI surveillance measures increasingly being used by the state or private agencies to ensure they are bias-proof? Presumably, it is not.
In my own experience of using an AI Assistant with consented data of positive voice involving 17 participants. The project was training a vulnerable group on collecting data on lived experiences. I found that LLM models started hallucinating and generalising sentiments, often making up the transcripts, which sounded genuine.
The Amsterdam case study has significant lessons for India’s AI policy makers and enthusiasts. India has declared its ambition to be a global leader in Artificial Intelligence (AI) governance. India is already embedding AI into defence, military, and financial hardware, giving it a strategic defence. As the world’s largest democracy and a tech-savvy nation, AI offers an opportunity for wider social good and to use it to leapfrog the current state of the digital divide. Not sufficiently training foundational AI models in Indian languages will miss the opportunity for India to leapfrog the digital divide. Data show that currently, Indian languages make up less than one per cent of online content.
That is, however, changing: in 2023, Indian AI startup, Sarvam AI, released the first open-source Hindi language model called OpenHathi-Hi-0.1. The AI model was the first in a series of models that will contribute to the ecosystem with open models and datasets to encourage innovation in Indian language AI. Google DeepMind is also actively working on supporting Indian languages, such as Morni, Multimodal Representation for India, which involves creating models that can understand a range of Indian languages and dialects.
India stands at a critical juncture. India has declared its ambition to be a global leader in Artificial Intelligence (AI) governance. As a tech-savvy nation, it is well-positioned to champion an inclusive human-centric approach. Unlike Amsterdam, which had robust regulatory frameworks yet still failed, India is building AI systems without comprehensive ethical guidelines. The lessons are clear: technical excellence alone cannot eliminate bias.
From my research experience, India might consider the following:
· Mandatory participatory design processes where affected communities help define problems before solutions are built.
· Bias auditing by researchers who understand marginalisation patterns, not just technical metrics.
· Making algorithmic decision-making processes public.
· For entrepreneurs working on developing AI products using data, it’s important to go beyond the usual market research. First-hand understanding of users’ needs are important,
India has the opportunity to pioneer inclusive AI development for the Global South. The question is whether we’ll choose innovation that empowers or excludes — and whether those most affected will have a meaningful voice in shaping that choice.

Why AI Policy Briefs are so US Centric? Media Bias in the AI Triad
Do You Remember the Early Days of Social Media?
It was while working on an assignment for my AI Governance course with BlueDot Impact that I stumbled on an uncomfortable truth: much of the AI discourse generated by large language models (LLMs) on governance, policy, and ethics is heavily tilted towards the United States.
The assignment itself was straightforward: explain the AI Triad (algorithms, data, compute) — the three core building blocks of AI systems. But as I experimented with two different AI models to draft a policy brief, I noticed something striking. Instead of producing globally balanced perspectives, the answers leaned toward Washington-style narratives of national security and U.S.–China rivalry.
This article grows out of that realization. It is not just about the AI Triad as a technical framework, but about how the “data” pillar of AI also shapes the way policy itself is narrated.
Claude: A Tutor’s Approach
Claude assumed I already knew something about the AI Triad. Instead of rushing into a polished answer, it asked clarifying questions:
- Which policymaker is this for?
- What’s the goal — to educate, advocate, or raise awareness?
This was helpful. Claude broke the Triad into multiple frameworks — technical, governance, and strategic. It even highlighted policymaking levels: local, state, federal, and international.
For a learner like me, this was valuable. It showed that the AI Triad isn’t one rigid concept. It can be understood differently depending on context.
Grok: US Centric Narrative
Grok’s response felt very different. It read like a polished U.S. policy memo.
It defined the AI Triad in dense technical terms (“pattern prediction,” “trial-and-error optimization,” “Moore’s Law”), tied it directly to U.S.–China competition, and then proposed policy recommendations such as expanding H-1B visas and tightening export controls.
It ended with a striking claim:
“The AI Triad demystifies AI’s black box, empowering policymakers to intervene precisely rather than reactively. Proactive governance will not only safeguard national security but position the U.S. as the global AI steward.”
Questioning the Bias
At that point, I challenged Grok directly:
Me: “You talk about U.S. global leadership; what informed your analysis? Why did you not talk from a more global context?”
Its reply was candid:
Grok: “This perspective is common in English-language policy resources and aligns with prominent AI policy debates that often center on U.S. national security and global leadership, given the geopolitical stakes (e.g., competition with China in AI development).”
Later, I pressed again:
Me: “Could I say that LLMs like Grok are deeply influenced by media discourses which in turn leads to structural bias?”
And Grok acknowledged:
Grok: “Yes, you could argue that large language models (LLMs) like me are influenced by media discourses, which can contribute to structural biases… The AI Triad’s ‘data’ pillar is the primary culprit. The bias is structural, not intentional, and stems from data curation challenges rather than deliberate design.”
This exchange made the bias visible: not deliberate, but structural, baked into the data the model had been trained on.
Three Voices, Three Framings
This becomes clearer when you compare three voices side by side:
U.S. policy framing (CISA):
“The U.S. government must marshal a national effort to defend critical infrastructure and government networks and assets, work with partners across government and industry, and expand services for federal agencies and operators.”
Grok echoing U.S. dominance:
“…position the U.S. as the global AI steward.”
India’s inclusive framing (#AIforAll):
“#AIforAll will aim at enhancing and empowering human capabilities to address the challenges of access, affordability, shortage and inconsistency of skilled expertise… India should strive to replicate these solutions in other similarly placed developing countries.”
One frames AI as a matter of security and competition.
The other frames AI as a tool for inclusion and development.
Both are legitimate — but only one tends to dominate the conversation, because of language, platforms, and media power.
Lessons on Mitigating Structural Bias
My experiment also revealed something hopeful: bias in LLMs is structural, but not fixed. When I pushed Grok to move beyond its U.S.-centric framing, it acknowledged the limitations and suggested ways to broaden the perspective.
Here are a few lessons that stand out:
- Diversify Training Data
Most AI models are overfed with U.S. and Western English-language sources. Incorporating non-English and Global South policy documents, media, and research outputs would reduce skew. - Prompt Engineering Matters
Users can play an active role. By explicitly asking for global or regional perspectives, as I did, we can force models to surface underrepresented narratives. - Amplify Non-U.S. Narratives
Countries like India, UAE, and Singapore are not absent from AI policy debates — their efforts are simply less amplified. Governments, think tanks, and academics from the Global South need to actively publish in English, contribute to global forums, and circulate their work in media ecosystems where AI models scrape their training data. - Policy Interventions
AI governance itself can address these gaps — for example, requiring transparency around datasets, promoting open repositories of policy documents, and encouraging partnerships with Global South institutions.
Why This Matters
The AI Triad (algorithms, data, compute) helps explain this structural bias:
- Algorithms are optimized to reproduce what’s statistically likely in English-language sources.
- Data is dominated by U.S. think tanks, media, and policy reports.
- Compute amplifies what’s most visible online — again, U.S. narratives.
The outcome: even when you ask for a “global brief,” the LLMs talk more about US policies.
A Reflection from India and the Global South
For India, building AI infrastructure is not enough. We also need to invest in think tanks, AI policy institutes, and public debate.
Right now, Indian media celebrates milestones — like space missions — but it rarely sustains discussions on the social aspects of AI: ethics, regulation, governance, and citizen participation. These must become national conversations — on television debates, in English-language newspapers, and across civic platforms.
The media’s role is to educate, excite, and sustain participation. The more active our media becomes, the more India’s voice will resonate globally.
AI cannot remain confined to government corridors. It has to enter the public imagination. Just as we proudly discuss space missions, we must also debate AI’s ethical risks, regulatory challenges, and opportunities for inclusion.
Only then will India’s achievements — and its frameworks like #AIforAll — stand alongside U.S. narratives on the global stage.


AI as a Digital Companion: an Indian perspective
Do You Remember the Early Days of Social Media?
One thought that often comes to mind when using tools like ChatGPT, Perplexity, and other generative AI models is how similar this feels to our early engagement with social media between 2006 and 2010. Social media was revolutionary back then — no one could have predicted how it would transform the world, but it was undeniably exciting. In India, platforms like Orkut paved the way before Facebook became dominant. For the first time, we could bring our personal lives online and connect socially in new ways.
I was in my early twenties in college, and like many others, I initially used social media to impress people I had a crush on. Looking back now, those moments feel a bit embarrassing — uploading things based on how we perceived the world then. Social media has since come full circle: from sparking optimism about human rights (like during the Arab Spring) to being weaponised for political agendas and increasing government surveillance. While still strong, its influence seems to be fading.
Technologies That Appeal to the Five Senses Make a Real Impact
Technology revolutions in India have always favoured those who are optimistic and at least somewhat educated in English. Today, an estimated 900 million Indians use various forms of social media. However, my travels to remote parts of India have shown me that technologies interfacing with our senses — particularly voice and sight — have had the most empowering impact on people with limited access to formal education.
For example, mobile phones allowed millions to leapfrog over the landline era. Similarly, voice- and sight-enabled services with simple interfaces transform lives today. India’s success with real-time digital payment systems like Google Pay or Paytm is a testament to this. Across the country, small vendors — whether literate or not — use these platforms seamlessly. Voice-enabled chat systems on WhatsApp are another game-changer.
Looking ahead, AI could address India’s chronic challenges in education. Generative AI might eliminate the need for traditional schooling by focusing on developing cognitive skills through local-language LLM models India plans to create. This could help overcome barriers like poor infrastructure, a lack of quality teachers, and the high cost of private education. While AI may not make us rich overnight, it holds the potential to make our lives significantly better by democratising access to knowledge.
It Will Be a While Before Generative AI Becomes a Mass Product
Generative AI tools like LLMs are far from being mass-market products yet. For instance, their responses varied widely when I asked ChatGPT and Perplexity about generative AI usage in India. Both models cited different sources but agreed that generative AI is primarily used by professionals, enterprises, and government bodies rather than the general population.
When I refined my query to ask about usage relative to India’s 1.4 billion people, I received an estimated 522.3 million users (around 37.3% of the population). Further narrowing my question to paying users yielded even more varied results: Perplexity estimated 52.22 million paying users based on hypothetical assumptions (10% of daily users). ChatGPT highlighted global figures without specific data for India.
This lack of precise data on paying subscribers across all LLM services is intriguing — and perhaps intentional. It underscores that while generative AI adoption is growing rapidly in India, it remains largely confined to niche segments. (see screen shots below)
Not All AI Tools Are Important for You: Master the Ones That Matter
With so many AI tools emerging daily, it’s easy to feel overwhelmed. However, experimenting with every tool isn’t practical or necessary. Instead, focus on mastering tools that align with your profession and personality.
For example, I work in research, humanitarian development, strategy, and communication. I’ve found that AI works best when paired with foundational knowledge gained through self-reading and critical thinking. It’s an excellent tool for brainstorming and fast research but should complement — not replace — your expertise.
Recently, I used ChatGPT to study intersectionality — a concept encompassing diversity across gender, race, ethnicity, and more in development programs. I achieved impressive results by cade-long experience in journalism and research with AI’s analytical capabilities. For instance, I guided ChatGPT using frameworks like “Analyze-Adapt-Access” while incorporating indicators like caste dynamics and historical context. The outcome was impactful because I controlled the inputs and leveraged my contextual understanding.
Watch Out for Short AI Courses and Keep Updating
To stay ahead in this fast-evolving field, invest time in learning how to use AI effectively:
Books: Ethan Mollick’s “Co-Intelligence — Living and Working with AI” offers practical advice on using AI as a co-worker or coach rather than just a tool.
Courses: Becki Salzman’s LinkedIn Learning course “Amplify Your Critical Thinking with Generative AI” introduces frameworks like PIQPACC that help frame better follow-up questions.
Custom Assistants: I created one tailored to my work needs after reading an HBR article on “How to Build Your Own AI Assitant” (e.g., ChatGPT’s “custom GPT”). These assistants store recurring prompts and background files for efficiency.
The key is treating AI as a digital companion — one that enhances your efficiency without replacing your expertise.
comparative answers Chat GPT and Perplexity.ai
How did I make use of AI to write this article?
After writing the first draft, I asked ChatGPT and Perplexity to give me feedback. After carefully reviewing the feedback, I incorporated the changes suggested by Perplexity. ai, as I felt that there were minor and more practical suggestions. Hers’s the screen shots.